
Das Forschungsprojekt Lagerbestandsüberwachung gehört genau wie unser Projekt RecoStation zu unserer langjährigen und spannenden Zusammenarbeit mit der HTW in Berlin. Es handelt sich hier um ein Wiedererkennungsverfahren mit dem Namen ELV.xD. Das ELV steht für das Ensemble-Learning-Verfahren und xD für den Einsatz von Tiefenkamera-Daten.
Für die Implementierung der automatisierten Lagerbestandsüberwachung am Beispiel unserer Modellfabrik fand sich schnell eine Gruppe von insgesamt drei Informatik-Studenten zusammen. Wie genau es den Berliner Studenten William, Mert und Viktor gelungen ist, das Projekt selbständig zu analysieren, zu strukturieren, zu entwerfen und unsere Idee auch umzusetzen, erfahren Sie in diesem Artikel.
Die automatisierte Lagerbestandsüberwachung ist ein Teil der Digitalisierung der Industrie, auch Industrie 4.0 genannt. Die Lagerbestandsüberwachung ermöglicht zu jedem Zeitpunkt eine genaue Übersicht des vorhandenen Lagerbestandes und verbessert so den Workflow in digitalisierten Industrien. Oder anders formuliert: Die KI-Technologie übernimmt Aufgaben, die niemand vermissen wird. Alle, die schon mal an einer Inventur teilgenommen haben, können sich bestimmt vorstellen, wovon hier die Rede ist.
Es gibt verschiedene Ansätze, eine automatische Lagerbestandsüberwachung umzusetzen. Zum Beispiel gibt es die Möglichkeit die Lager mit Scannern zu bestücken und die Produkte zu markieren (z.B. mit NFC oder QR-Codes, letzteres gehört auch zu unseren Spezialitäten, aber hier geht es jetzt um die KI-Technologie). In diesem Projekt wurde der Lagerbestand mit einer Kamera erfasst. Es wurde Deeplearning verwendet, um das Kamerabild auszuwerten und die Lagerbestände und leeren Lager im Foto zu erkennen.
Deeplearning ist ein Teilgebiet des Machinelearnings. Beim Machine- und Deeplearning wird ein Modell mit Daten darauf trainiert, Strukturen zu erkennen. Dabei wird Deeplearning für unstrukturiertere Daten wie zum Beispiel Musik, Texte oder Bilder verwendet. Deeplearning verwendet so genannte neuronale Netze, die dem menschlichen Gehirn nachempfunden sind.
Das Ziel des Projektes war es, ein neuronales Netz mit Bildern der Modellfabrik auf das Erkennen der Lagerbestände zu trainieren. Die fertige Lagerbestandsüberwachung sollte dann wie folgt funktionieren:
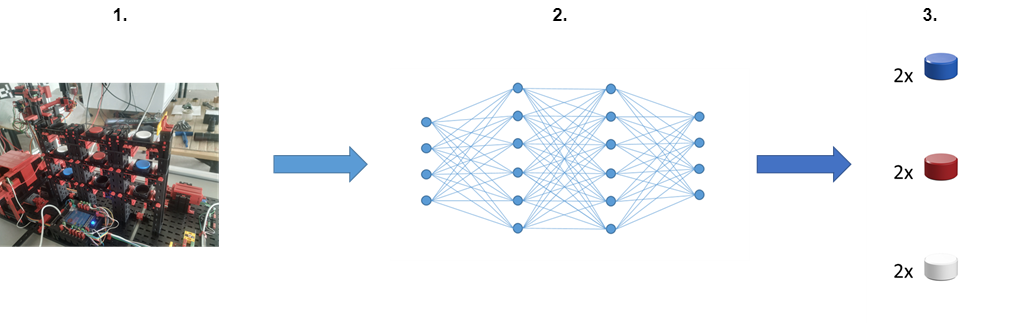
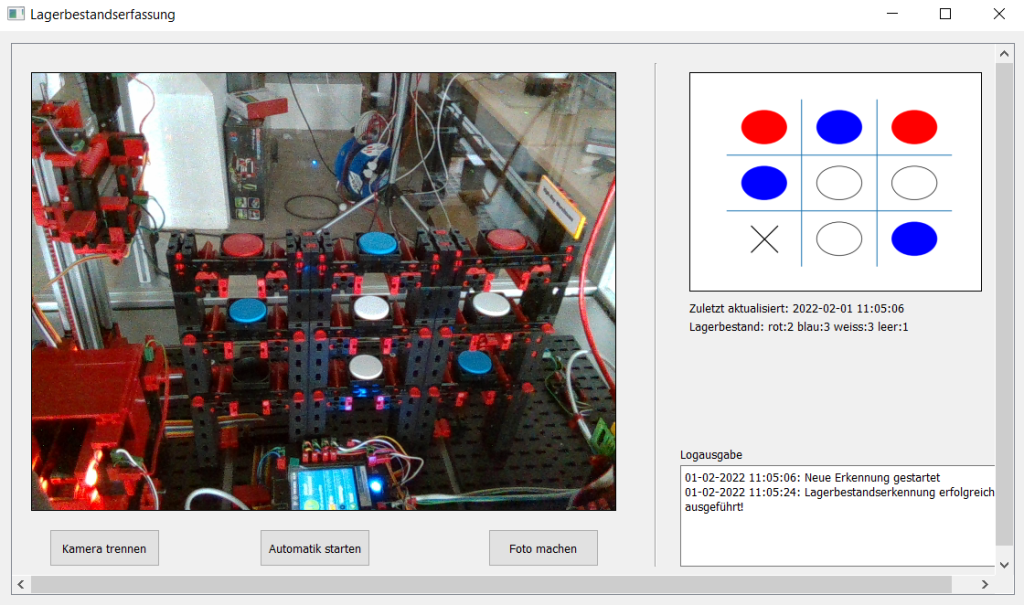
Der Lagerbestandserkennungsprozess sollte über eine Benutzeroberfläche steuerbar sein. Es sollte die Möglichkeit geben, eine einmalige sowie eine automatische (sich wiederholende) Lagerbestandserfassung zu starten. Die Ergebnisse der Erfassungen sollten sowohl in einer Datenbank abgespeichert als auch auf der Benutzeroberfläche grafisch dargestellt werden.
Zuerst analysierten die Studierenden das vorliegende Lastenheft, in dem Anforderungen und Rahmenbedingungen hinterlegt sind, und erarbeiteten daraus eine technische Spezifikation, die unter anderem Abnahmekriterien, einen Entwurf der Benutzeroberfläche, Anwendungsfälle und einen Architekturentwurf beinhaltete.
Die Implementierung teilt sich nach dem Vorgehensmodell „Scrum“ in drei Arbeitsabschnitte (Sprints) auf. Diese dauern jeweils drei bis vier Wochen. Der dementsprechend nächste Schritt war die Sprintplanung. Diese beinhaltete das Definieren von Arbeitspaketen und das Verteilen dieser auf die drei Sprints.
Im ersten Sprint hatte die Gruppe Fotos der Modellfabrik gemacht, gelabelt und damit bereits das Training des neuronalen Netzes angefangen. Außerdem gab es schon eine simple Benutzeroberfläche und die Schnittstellen zwischen Benutzeroberfläche, Backend und dem trainierten Modell waren vorhanden. Außerdem konnte schon ein erster Lagerbestandserkennungsdurchlauf anhand von lokalen Bildern gestartet werden. Als Ergebnis wurde auf der Benutzeroberfläche das Bild mit Markierungen der Lagerbestände angezeigt.
Im zweiten Sprint wurde die Kamera miteingebunden, sodass ein Livekamerabild in der Benutzeroberfläche angezeigt werden konnte. Außerdem konnte eine Lagerbestandserkennung anhand des Kamerabilds durchgeführt werden. Zudem wurden nun auch die Positionen der Produkte im Lager berechnet, damit nicht nur die Anzahl, sondern auch die Positionen der Lagerbestände als Ergebnis vorhanden waren.
Im dritten und somit auch letzten Sprint wurde die Datenbankeinbindung vorgenommen, sodass Ergebnisse in der Datenbank gespeichert wurden. Außerdem wurde die Benutzeroberfläche um ein Ereignis/Error-Log erweitert. Dieses loggt die Ereignisse und auftretende Fehler während der Lagerbestandserkennung. Auftretende Fehler werden zudem in der Datenbank geloggt.
Weiterhin wurden im dritten Sprint ein paar Verbesserungen an der Benutzeroberfläche vorgenommen und das neuronale Netz wurde mit noch mehr Bildern des Lagerbestandes trainiert.
Da es sich um eine komplexe Thematik handelt, mit der die Studenten zuvor noch keinen bzw. wenig Kontakt hatten, war es natürlich anstrengend, sich erstmal in das Thema einzuarbeiten und zu informieren. Technische Schwierigkeiten hat aber vor allem das Training bereitet. Dieses hat, ab einer gewissen Anzahl an Bildern, die Leistungsfähigkeit der Rechner von den Studenten überfordert. Es war also zwischendurch immer wieder genug Wartezeit vorhanden, um den erforderlichen Kaffee zu kochen.
Was unsere Studenten innerhalb eines Semesters für einen Prototypen erreicht haben, ist übrigens auch in der Praxis möglich. Wenn Sie mehr über die pragmatische Integration von KI in Arbeitsabläufen erfahren möchten, beraten wir Sie gern.


Klimaschutz und Nachhaltigkeit sind sehr wichtige Themen für uns. Deshalb beteiligen wir uns am Berliner Stadtbaum-Projekt. Denn jeder Baum zählt.

Software entwickeln lassen oder gleich selber programmieren? ✓ Strategien ✓ Kosten ✓ Dienstleistungen. Der Überblick für Digitalisierungs-Einsteiger!

Freizeitbeschäftigungen dürfen nicht einfach nur zu weiteren Terminen werden. Wie sich ein Hobby zur Seelentankstelle entwicklen kann, erfährst Du in unserem Blog-Artikel von unserem SAP-Berater Jörg aus Berlin.